Train Your Own Reranker
 Read on Substack
Read on Substack
August 10, 2025
This article dives into RCAccelerator, a tool for automating Root Cause Analysis (RCA) of CI failures. Here, I’ll focus on one key component: the reranking process 🔢.
✅ What we will cover in this article is:
- A high-level overview of the RCAccelerator pipeline (Part I)
- A user-friendly closer look at the reranking process (Part II)
- A practical example showing how to train a reranking model using bert-base-uncased model and the MS MARCO dataset (Part III)
Part I: A High-Level Overview Of The RCAccelerator Pipeline
Let’s take a closer look at how we store data from Jira, user documentation, and other sources into the vector database and how we retrieve data from the vector database later. Storing the document chunks into the vector database can be split into the following steps:
-
We collect data from various sources (e.g., Jira, user documentation, …). I’ll refer to this data as text chunks or documents.
-
We compute embeddings for each text chunk using an embedding model.
-
The embeddings, along with the corresponding text chunks, are stored in a vector database.
Later, when the user inputs an error description or traceback, we follow these steps to retrieve the relevant information for the generative model (the LLM that processes the chunks from the vector database along with the user query to produce the final solution) from the vector database:
-
We compute an embedding for the user’s query.
-
Using this embedding, we retrieve relevant documents (text chunks) from the vector database based on cosine similarity.
-
We then rerank the retrieved chunks using a reranking model and pass top K documents along with the user query to the LLM.
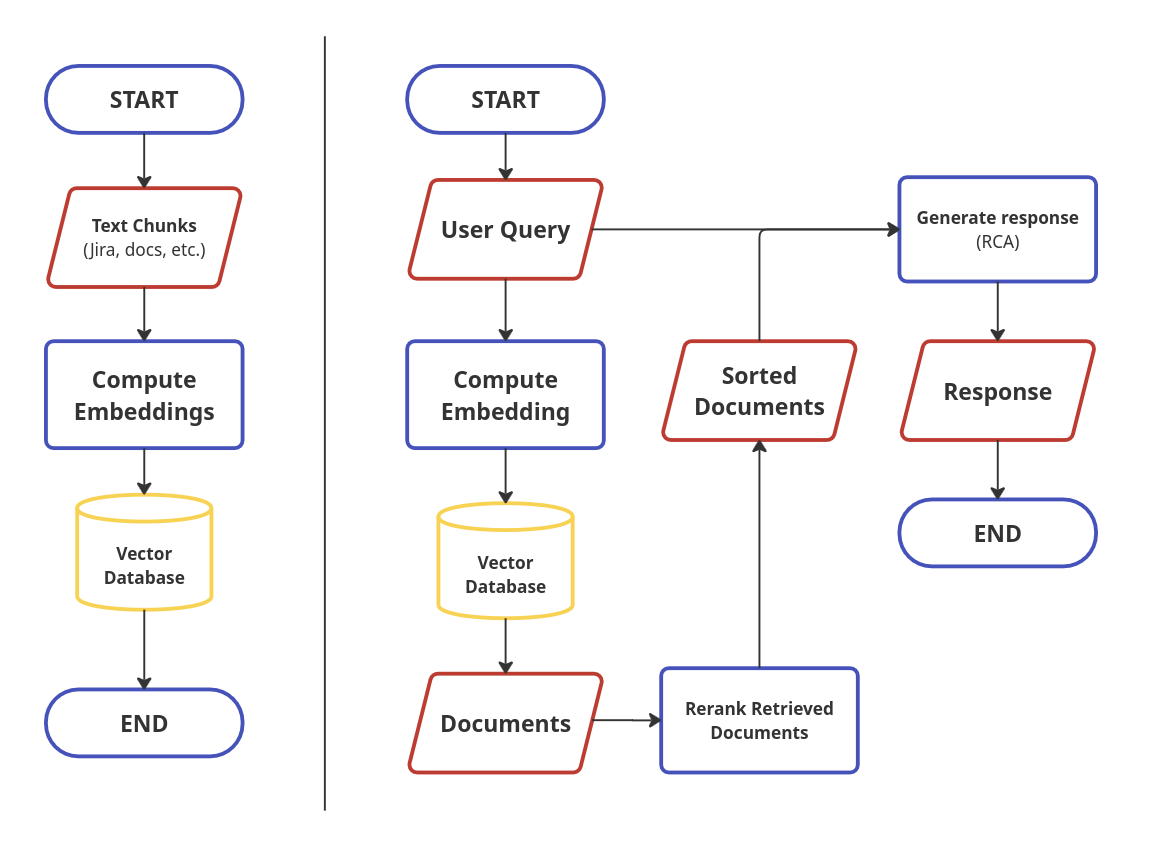
(Picture 1) Flowchart for the RCAccelerator. Left: process that stores knowledge from sources like Jira or user documentation into the vector database. Right: process that handles user query (description of a problem) and generates a response that contains solution for the problem.
Part II: A User-Friendly Closer Look At The Rerank Model
Now the question might arise: Why do we need a reranker, and how do these two models (embedding and rerank) work together?
I like to think of the process of retrieving information from the vector database using the embedding and reranking model as visiting a library. First, the embedding model helps you find the right section of the library where the book you’re looking for might be. Then, the reranking model helps you pick the best book in that section that actually answers your question.
The embedding model has a limited number of dimensions to represent the meaning of a piece of text. As a result, using only embeddings can sometimes retrieve results that aren’t very relevant for the user’s question. For example, if we keep things simple, if the user’s question is: “How do solar panels generate electricity?” then the vector database might return the following chunks of text:
- ❌ “Battery storage systems can store energy from solar panels for use at night.”
- ❌ “Electric cars are gaining popularity due to improvements in battery technology.”
- ✅ “Solar panels convert sunlight into electricity using photovoltaic cells.”
- ❌ “You can send excess electricity back to the grid in exchange for energy credits.”
- ❌ “Solar panel efficiency is affected by factors such as temperature, shading, and angle of installation.”
Notice that all the retrieved chunks are at least somewhat related to the user’s question but not all of them contain information needed to answer the question. In this case there is only one sentence that helps to answer it. Once we apply the reranking model, if everything goes smoothly, the list will look like this:
- ✅ “Solar panels convert sunlight into electricity using photovoltaic cells.”
- ❌ “Battery storage systems can store energy from solar panels for use at night.”
- ❌ “Electric cars are gaining popularity due to improvements in battery technology.”
- ❌ “You can send excess electricity back to the grid in exchange for energy credits.”
- ❌ “Solar panel efficiency is affected by factors such as temperature, shading, and angle of installation.”
The reranking model can take a look more in depth at the user’s query and a specific chunk retrieved from the vector database and decide whether it is relevant to the user’s question or not. It has the ability to compare the user’s query and the retrieved chunks on a token level. This is something that is not possible using solely an embedding.
Now I hear another question, which is: “Why not use the rerank model to query the vector database directly?”
The short answer: computation cost. Running a rerank process usually involves passing individual pairs of query and retrieved documents to the rerank model. If your vector database contains let’s say 1M documents then you would have to call the rerank model 1M times which might take quite a lot of time. Using the embedding model first allows us to cut down significantly the amount of comparisons we have to compute. This is the reason we:
- compute the query embedding once
- use that embedding to query the vector database
- and then rerank (using the rerank model) only a small subset of all the data stored in the vector database.
This significantly reduces the overall computation while still delivering relevant results.
Part III: Train Your Own Reranker
If you enjoyed this blog post up until now, then I believe you’ll enjoy this part. In this section, we’ll take a look at fine-tuning a bert-base-uncased model on the MS MARCO dataset, ultimately training our own simple reranking model. The goal is not to build a state-of-the-art reranker, but rather to demonstrate the basic idea and see whether we can observe any improvement with training and behavior that at least remotely resembles that of a reranker. If you want to follow along, then you can check out the Jupyter notebook 📚 I used for the fine-tuning.

(Picture 2) MS MARCO Dataset. The dataset contains the following features: answers, passages, query, query_id, query_type and wellFormedAnswers. For the purpose of training a reranker we will suffice with query and passages. The passages field contains two subfields: is_selected and passages_text. The is_selected subfield specifies whether a given passage is relevant to the user query.
As already stated, we are going to use the MS MARCO dataset (Picture 2). We are interested in these two values from the dataset:
- Query: The user’s question.
- Passages: Retrieved documents from the vector database, each
document is labeled with:
- 1 = if the document is relevant to the user’s question or
- 0 = if the document is irrelevant to the user’s question.
As an evaluation metric, we are going to use Top-K Accuracy and MRR@10 (Mean Reciprocal Rank). For example, a value of Top-1 Accuracy 0.5 means that for 50% of the data points from the test dataset, the model was capable of placing the correct text chunk in the first position after the reranking. And an MRR@10 value of 0.5 can be interpreted (with closed eyes) to mean that, on average, the first relevant document is found at rank 2 after re-ranking.
There are many data points in the training set, so we’ll fine-tune the model on just a subset of it. Our goal is simple: beat the non-fine-tuned model. The bar is really low :). Which brings us to the bert-base-uncased model. If we take a look at how it performs, we can see, unsurprisingly, that the performance before fine-tuning is really low and close to a model which would pick the most relevant document randomly.
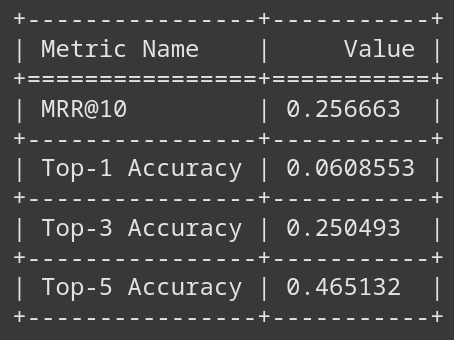
(Picture 3) Pre Fine-Tuning (bert-base-uncased)
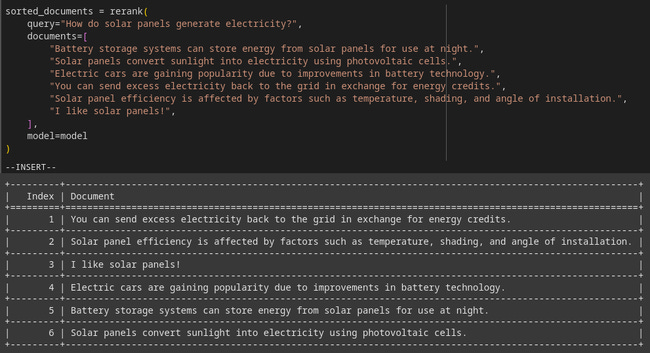
(Picture 4) An example of reranking of documents related to question: “How do solar panels generate electricity?”. Here the non fine-tuned model is used. Notice that the document that contains the answer to the question is ranked last.
Let’s improve upon this. The bert-base-uncased model is a strong candidate for our task. BERT was trained on the two following tasks, each of which makes it a good (note: probably not the best one) base model for a reranker:
- Predicting masked words in a sentence: “[CLS] How are [MASK]? I am fine.” -> you
- Determining if one sentence follows another: “[CLS] How are you? [SEP] I am fine.” -> yes, while “How are you? [SEP] The weather is nice today.” -> no
If we take a look at how does the model perform out-of-the-box on our reranking example, we see it doesn’t do a great job. The model places irrelevant sentences like: “I like solar panels!” above the document that actually contains the information needed to answer the user’s question (see Picture 4). This is something we’ll try to improve.
We are going to train the model as follows. For each training sample:
- We pass ten candidate sentences to the model.
- It outputs relevance scores.
- We calculate listwise softmax cross-entropy loss over the entire list, encouraging the model to assign higher scores to relevant chunks and lower scores to irrelevant ones. Note: we lose score interpretability here. A score of -4 could still mean a chunk is the most relevant. It is the order in the end that matters, not the score itself.
I won’t go deep into hyperparameter tuning here. You can explore all the details in the Jupyter notebook 📚 itself. I left the hyperparameters unchanged. Here’s a look at the performance after a brief round of fine-tuning (single epoch):
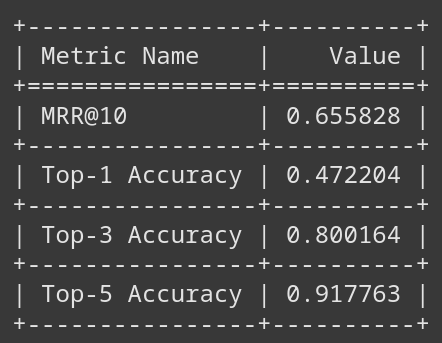
(Picture 5) Post Fine-Tuning (bert-base-uncased)
Notice that the MRR@10 increased significantly as the Top-1 Accuracy did. For 80% of the data points in the test dataset, the model has put the correct document into the top 3 documents out of 10. This is not state-of-the-art and production ready result but clearly hit the goal we aimed for. Now, let’s test the model with the query and document chunks we used prior to testing of the model. Did the model improve?
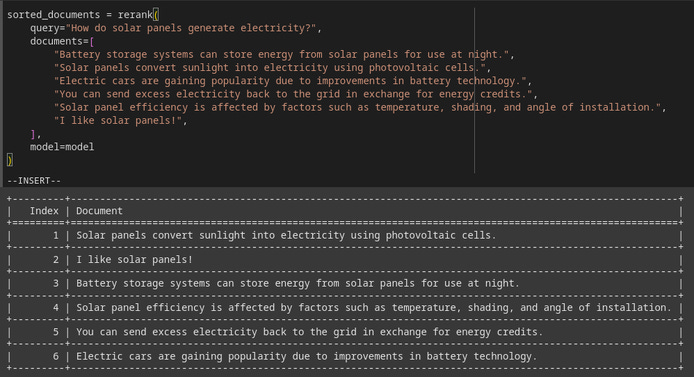
(Picture 6) An example of reranking of documents related to question: “How do solar panels generate electricity?”. Notice that the fine-tuned model successfully put the document that contains the answer to that question on the first place (‘Solar panels convert sunlight into electricity using photovoltaic cells.’).
It did! 🎉 Notice, that on the first place there is the correct document containing the answer to the question of: “How do solar panels generate electricity?” (see Picture 6):
“Solar panels convert sunlight into electricity using photovoltaic cells.”
And that’s it. We trained our own rerank model. There are many things we can try to improve the performance like training the model on the entire dataset from MS MARCO, using a different base model or a better searching through the hyperparameters space. But for now, we have demonstrated that even with a relatively quick training and bert-base-uncased model, it’s possible to relatively quickly get a model that exhibits behavior of a reranker.
Thanks for reading till the end! 👋